在人工智能技术飞速发展的今天,大语言模型已成为推动科技进步的重要引擎。然而,当这些模型面对长文本处理任务时,一个根本性的技术瓶颈始终困扰着研究者:全注意力机制带来的二次方计算复杂度,严重限制了模型的推理效率。为了解决这一世界性难题,腾讯优图实验室与伦敦国王学院联合提出了一项突破性的研究成果——SSA(Sparse Sparse Attention)训练框架,这一创新方法不仅在国际权威评测中展现出卓越性能,更在理论上为稀疏注意力训练开辟了全新的路径。
传统稀疏注意力方法通过限制每个查询仅关注部分历史token来缓解计算复杂度问题,但无需训练的稀疏策略往往导致模型性能显著下降。而现有的原生稀疏注意力方法虽然通过端到端训练改善了这一状况,却又陷入了一个关键悖论:模型学习到的注意力模式反而比全注意力模型更加稠密,这实质上削弱了稀疏化的有效性。这一现象的根本原因在于梯度更新的缺陷——那些未被稀疏机制选中的键值对在前向传播中被跳过,无法获得梯度更新,导致模型无法学会自我抑制,最终使得稀疏训练的效果大打折扣。
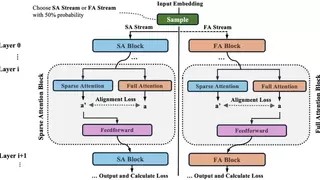
腾讯优图与伦敦国王学院的研究团队提出的SSA训练框架,巧妙地解决了这一难题。该框架在每一层同时引入稀疏注意力与全注意力,并强制二者输出双向对齐。这一设计的精妙之处在于,它保留了所有token的梯度流,使模型能够主动学习有效的稀疏模式,而非被动地进行剪枝。从技术实现上看,SSA设计了两个优化的目标:一是标准的下一词预测交叉熵损失,在稀疏与全注意力模式下以相等概率采样计算;二是层级别的双向对齐损失,用以约束稀疏注意力与全注意力输出的一致性。
在训练过程中,SSA以相等概率交替采用全注意力与稀疏注意力模式。这种双模训练的设计有两个深层考量:一方面,全注意力能够自然形成更具区分度、天然自稀疏的注意力分布;另一方面,稀疏注意力更贴近实际推理时的运行方式。为了控制计算开销,并确保模型在训练中处理的token总量与基线方法一致,研究者并未同时优化两种模式的损失,而是交替进行更新,这一巧妙的设计在保证训练效率的同时,最大程度地发挥了双模训练的优势。
SSA框架的核心创新在于其对偶注意力对齐机制。在每一层中,除当前主干路径所采用的注意力模式外,额外计算其对应相反模式的辅助注意力输出。这一辅助计算仅用于对齐目标,不参与后续层的前向传播,从而在不过度增加计算负担的前提下,实现了两种注意力模式的深度对齐。对齐目标由两个互补的组件组成:稀疏性损失促进全注意力输出模仿稀疏注意力输出,从而形成更稀疏和更具选择性的注意力分布;对齐损失则对稀疏注意力输出施加正则化,使其与全注意力输出保持一致。这种双向对齐机制协同作用,一方面促使全注意力在训练过程中自然趋向更稀疏的分布,另一方面确保稀疏注意力分支在训练中保持稳定。
实验结果表明,SSA在多个常识推理基准上达到了稀疏与全注意力推理下的SOTA水平。在语言建模能力评估中,SSA通过引入稀疏训练路径和对齐损失,在保持全注意力性能的同时,显著提升了稀疏推理质量。其核心机制是对齐损失促使全注意力分布变得更稀疏,从而减少与稀疏注意力在推理测试时的表达差异。在PIQA、Hellaswag、ARC-Easy以及ARC-Challenge这些常识推理任务中,SSA不仅优于所有稀疏基线,甚至以仅256Token的感受视野超越了全注意力模型。
更为引人注目的是,SSA展现出在不同稀疏程度下的优异外推能力。随着稀疏注意力中token数量增加,其在各项任务上的性能基本呈单调提升,这一特性使得模型能够支持灵活的计算-性能权衡,为实际应用中的资源分配提供了更大的弹性空间。在长上下文评估中,SSA的表现尤为突出。在大海捞针任务中,SSA在几乎所有感受视野下均为最强的稀疏注意力方法,并在全注意力推理下达到100%准确率。当上下文长度超过训练最大长度时,全注意力模型性能骤降至0%,而经稀疏注意力训练的模型仍保持非零检索能力,这充分证明了SSA在超长序列处理上的强大泛化能力。
从技术发展的角度看,SSA框架的提出标志着稀疏注意力研究进入了一个新阶段。传统方法往往在效率与效果之间艰难权衡,而SSA通过创新的训练机制,实现了二者之间的协同提升。这一突破不仅对大语言模型的实用化部署具有重要意义,也为后续的注意力机制研究提供了新的思路。在人工智能模型规模不断扩大的今天,计算效率已成为制约技术发展的关键因素之一,SSA所展现的技术路径,或许将为解决这一挑战提供重要的参考。
腾讯优图实验室的这一研究成果,再次证明了中国AI团队在前沿基础研究领域的实力。当全球AI竞争日益聚焦于底层技术创新,中国科研团队正通过扎实的研究工作,在国际学术界发出越来越响亮的声音。SSA框架的开源发布,将进一步推动全球AI社区在注意力机制优化方面的研究进展,为构建更高效、更智能的大语言模型生态系统贡献力量。
随着人工智能技术向更复杂、更实用的方向发展,对长文本处理能力的需求将日益增长。SSA框架所展现的技术优势,不仅能够提升现有模型的处理效率,更为未来的多模态、跨领域AI应用奠定了重要基础。当AI系统需要理解整本书籍、分析长篇报告或处理持续对话时,高效的注意力机制将成为实现这些目标的关键技术支撑。腾讯优图的这一创新,正是在为这样的未来铺平道路。
在人工智能技术快速演进的浪潮中,基础研究的突破往往能够引发连锁反应,推动整个技术栈的进步。SSA训练框架的成功,不仅是一次技术上的胜利,更是中国AI研究实力在国际舞台上的一次精彩展示。当更多像腾讯优图这样的团队在前沿领域持续深耕,中国在全球人工智能创新版图中的地位必将更加稳固,为人类智能技术的发展贡献更多中国智慧与中国方案。



